Projects
Objective: To build a lightweight model (limiting parameters and multiplies) that maintains a high degree of accuracy
in classifying speech keyword audio samples.
Key Idea: Try to limit the number of parameters and multiplies of the model, making it as lightweight as possible,
while maintaining decent categorical accuracy. For this, I utilize varying strides and pooling sizes, adding image
enhancing techniques (like Gaussian and Sobel convolutions) and addition of Non-Linear LoRA Layer and Channel Attention Blocks (CAB).
Dataset: Google Speech Commands Dataset is chosen so as to cover a wide array of speech sounds as trainable data. The model is
trained on a subset of 8 classes (chosen to span the range of speech sounds), with 3000 audio samples each. Additionally, the model
is tested on the standard V12 dataset, a 12-keyword subset of the same dataset, which enables fair comparison with other
performing models.
Challenges and Methods
For Spectrogram:
- Number of Mel Bins: I chose the standard value of 40 bins, despite larger bin numbers providing more information. Larger bins increase input size and computational complexity, which is undesirable for a lightweight model.
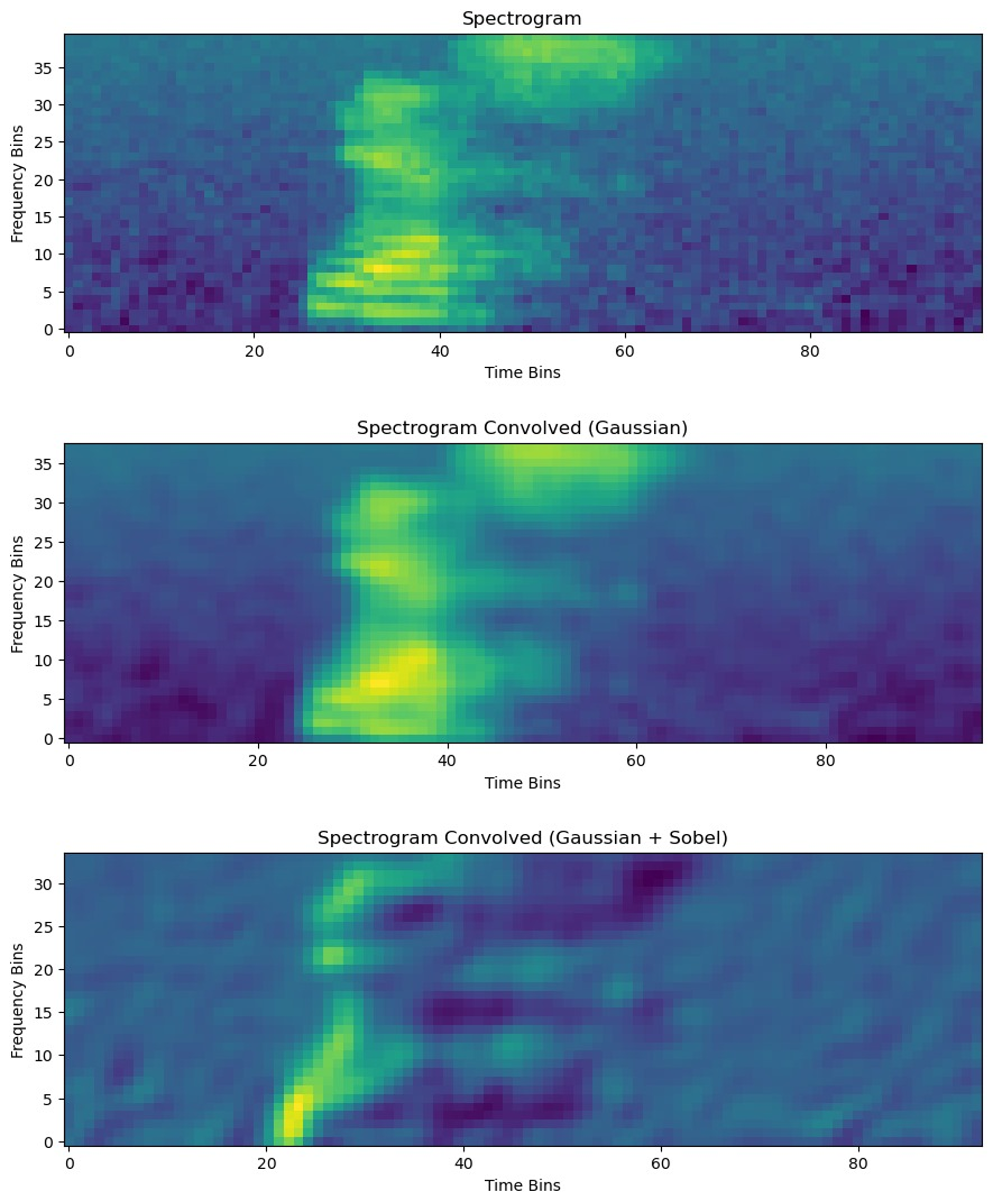
- Adding Gaussian White Noise: To deal with zero paddings and sharp boundaries in the input signal, we augment the input signal with gaussian white noise. This makes the spectrogram devoid of sharp breaks. See Figure 1.
-
Spectrogram Enhancement: Two approaches are tried. See Figure 2.
- Gaussian Filter: Smoothens out the noisy edges present and prevent model overfitting on the noise.
- Gaussian + Sobel Filter: Sobel filter is applied along x and y directions, and added up. Gaussian smoothening is done before and after the above. This highlights the edges and provides a depth to the image. See Figure 3.
For MFCC:
- Appending additional features: Features like Delta, Delta-Delta and Energy are appended to the MFCC frames to add more context and information.
This approach updates parameters in a lower-dimensional space, effectively reducing the model's parameter load. Applying a non-linear activation function ensures the layer remains non-linear.
I expect this Non-Linear LoRA Layer with 64 nodes and a rank of 32 to outperform a traditional dense layer with 32 nodes. This hypothesis is tested in the results section.
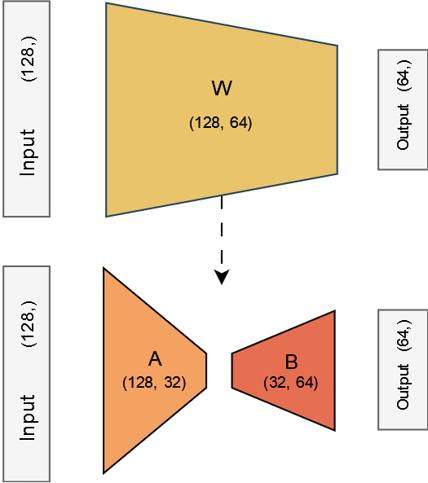
The method involves making a copy of the input (e.g., shape 15x15x64), normalizing it, and passing it through a Dense layer with 64 nodes (matching the number of channels) and Sigmoid activation. This Dense layer connects channels, enabling inter-channel communication. The resulting tensor, of the same shape as the input, is multiplied with the original input, effectively weighting the channels based on learned importance scores.

-
Deep Neural Networks (DNN): Follows the standard architecture of having 3 hidden layers, along
with measures against overfitting like L2 Regularization and Dropout (0.25). It will be shown that this standard architecture is not an efficient one, and any enhancements must lead to
an increase in parameters, which is not desired.
- dnn_3x128: 3 hidden layers with 128 nodes each. Number of parameters: 184k.
-
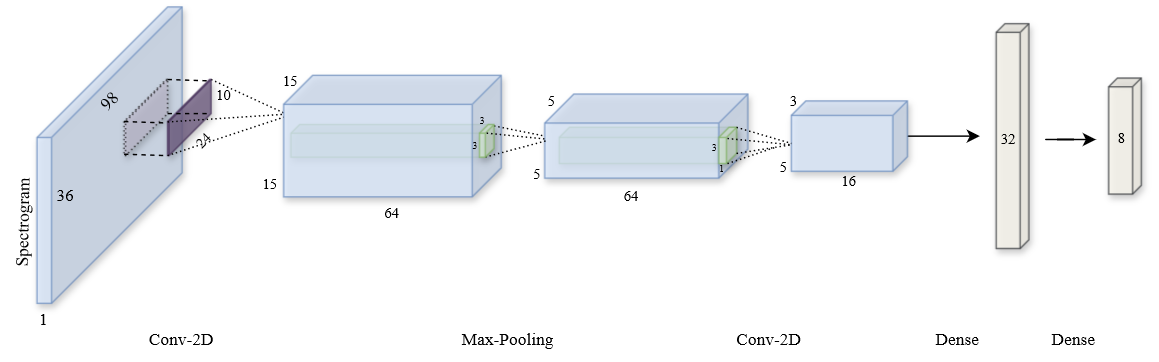
Convolutional Neural Networks (CNN): The model consists of two convolutional hidden layers, with a Max Pooling layer
after the first, followed by a dense hidden layer of 32 nodes. Regularization techniques such as Dropout (0.25) and L2 Regularization
are applied.
Constraints and Tuning:-
Convolutional Layers: Limiting number to two layers, as this will reduce the parameters and multiplies.
- Kernel Size: Set to 1/4 and 1/3 of the input image size, capturing the essential global features of the spectrogram.
- Stride Length: 1/5 of the kernel size, maintaining a slight overlap for context.
- Pooling: Emphasized more on the time axis than the frequency axis to focus on frequency variations, using a (3, 2) pool size.
Models Considered:
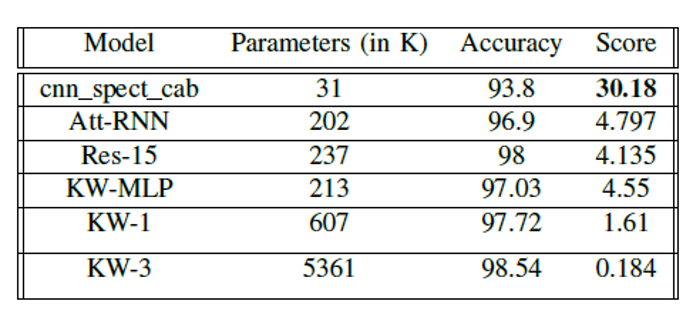
- cnn_spect: Having Spectrogram as input, with architecture as mentioned above. This contains 26k parameters.
- cnn_mfcc: Having MFCC (with additional delta parameters) as input, the above architecture is slightly modified. No pooling or striding is done as each value corresponds to a unique and relevant feature value. Also, an additional Dense layer of 64 nodes is added for processing the features well. This contains 97k parameters.

Comparison with Filters
We see that the gaussian filter and no filter are better than using sobel filter. This might mean that using no filter is a better approach. However, we notice that the variability in each class training is lesser when using gaussian filters, than using no filter at all. Thus, we prefer gaussian filters since this makes the model more stable and reliable.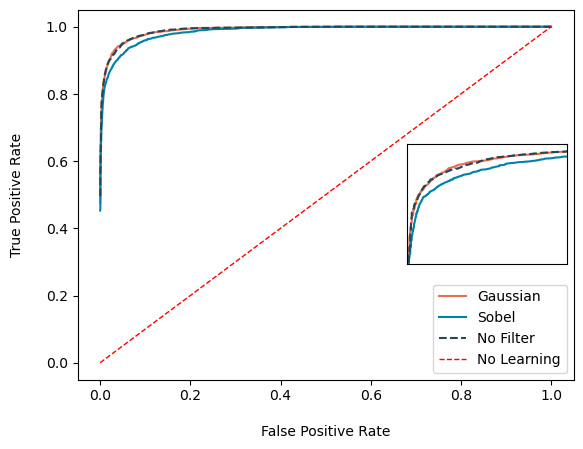
Comparing DNN Enhancements
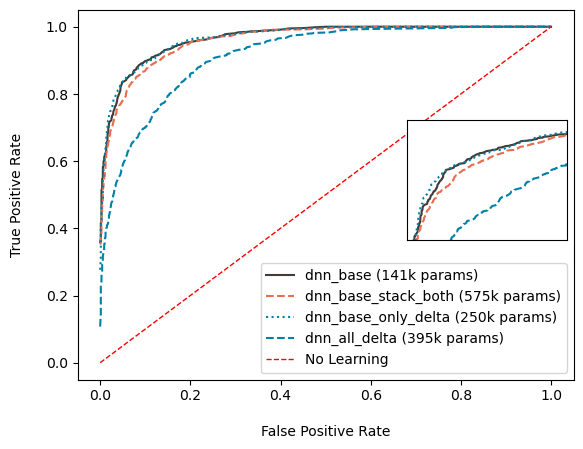
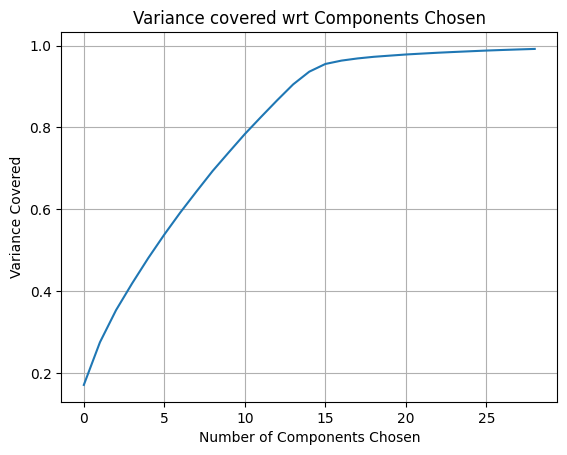
The standard DNN architecture with minimal layers performs poorly, even with enhancements. While deeper dense architectures might help, they increase the parameter count (as seen in the first figure below), which is undesirable. Using methods like stacking and adding delta features do not work likely due to DNN's limited capacity to process spatio-temporal information. Overall, DNN enhancements fail to produce a model that is both accurate and compact.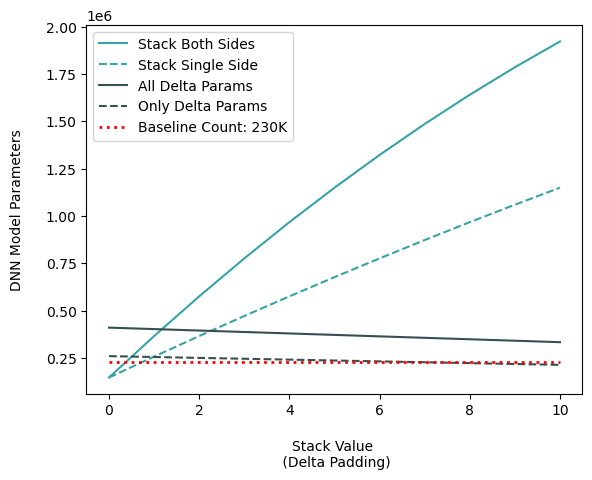
Comparison using Non-Linear LoRA Layers
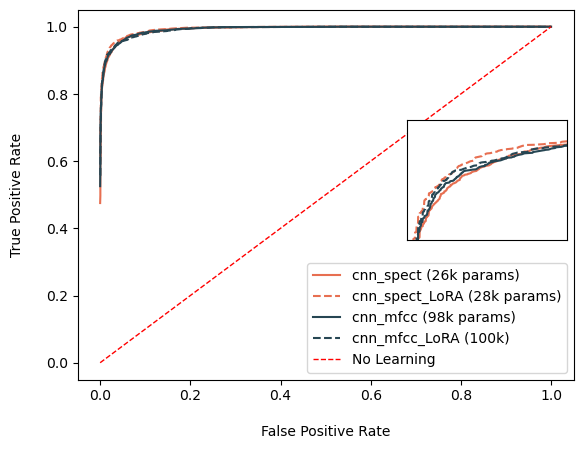
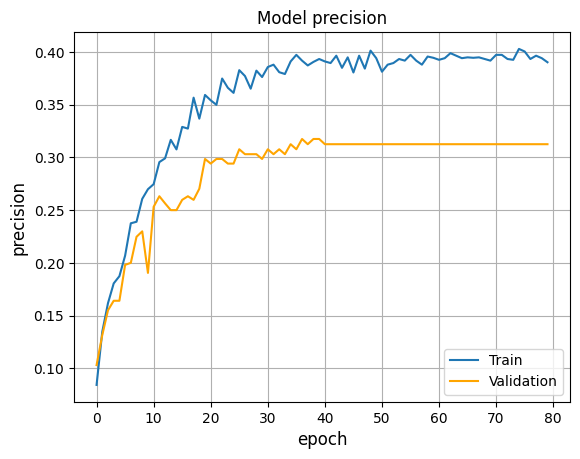
Firstly, the ROC curves for both cnn spect and cnn mfcc are similar, with categorical accuracy around 90% (±0.16). However, cnn_mfcc has about four times more parameters, meaning cnn_spect achieves similar accuracy with fewer parameters.Secondly, the LoRA layers do not seem to contribute much, although a slight improvement is noted. The accuracy values increase by 0.5%. This seems promising, and this layer might be better suited for large networks that require a necessary decrease in computational load. In lightweight models, this layer does not help.
Comparison of Best Models with Non-Linear LoRA
There is significant improvement in performance, in both cases for cnn_spect and cnn_mfcc, when applying the Channel Attention Block (CAB). For cnn spect, the categorical accuracy increased to 93.8% (±0.167). This shows that apart from the spatial analysis done using CNNs, pairing it up with a channel based analysis using CAB helps improve performance.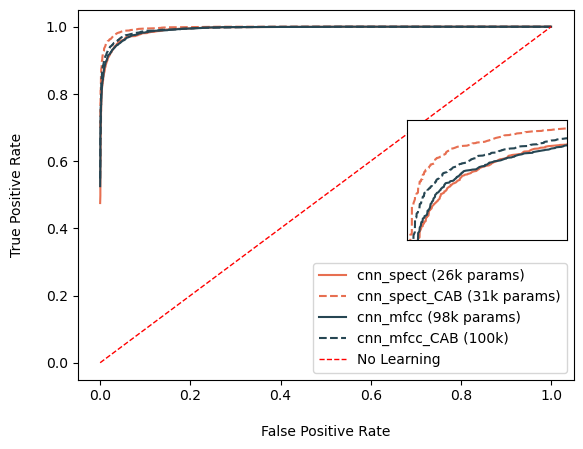
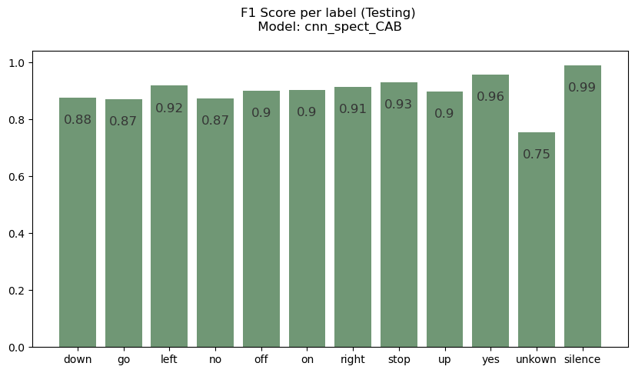
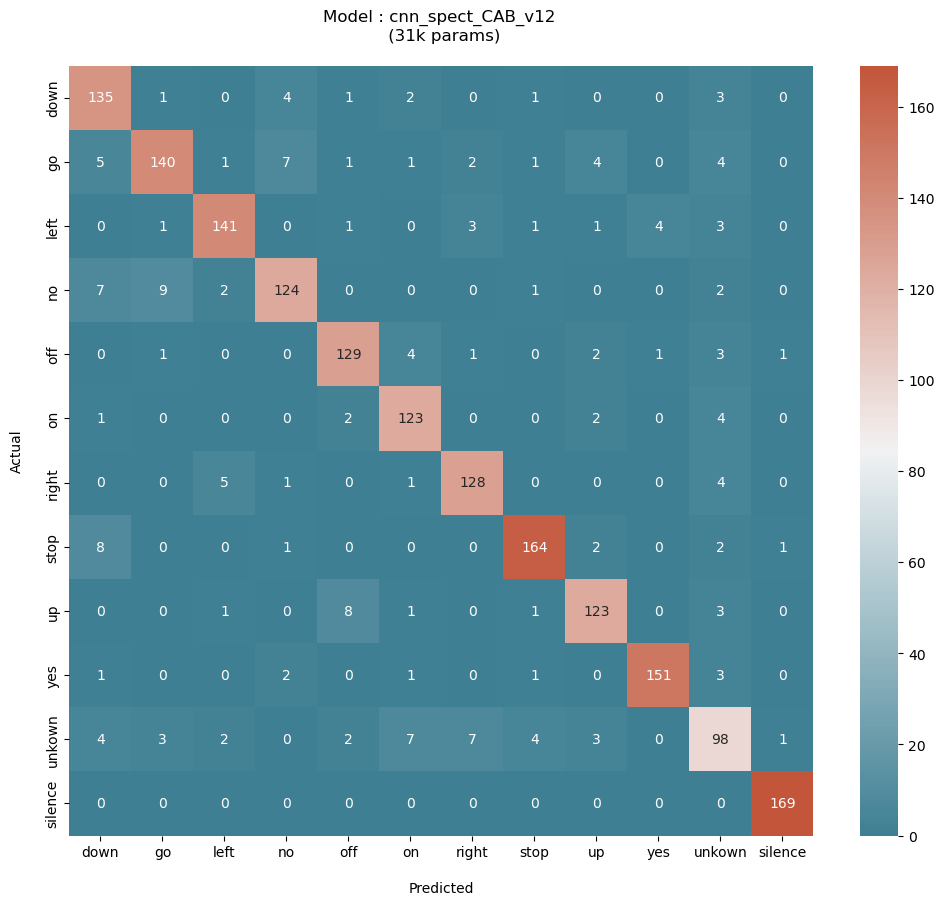
Confusion Matrices on Test Sets
Trained the best model architecture (cnn_spect_cab) on two different datasets, one with a 8-keyword subset and the other being the V12 dataset. The classes were chosen so as to challenge the model while covering the range of keyword phonetics. It is observed that this architecture performs equally well on both the test sets, with a categorical accuracy of greater than 90% categorical accuracy.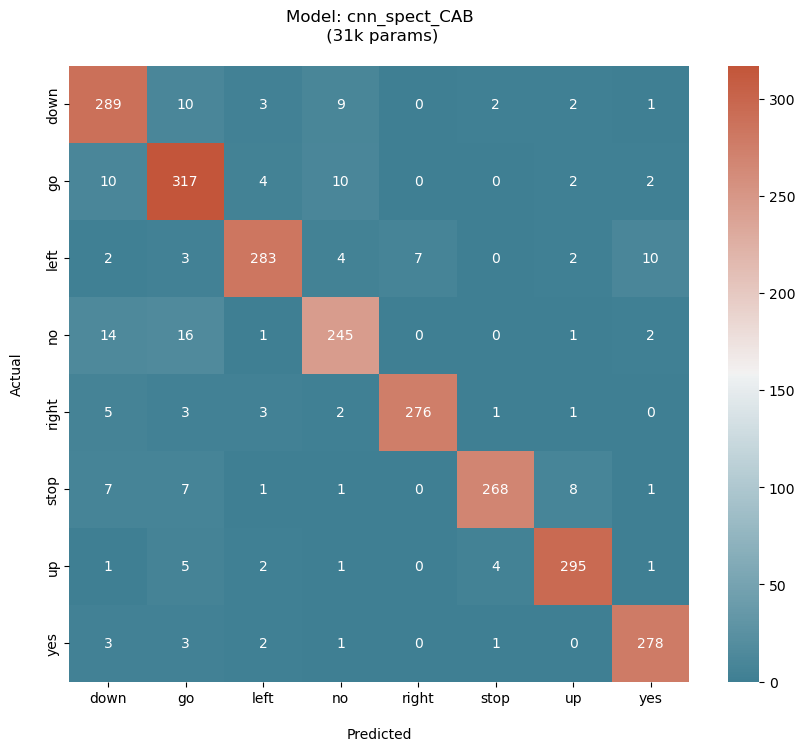
Objective: We aim to improve performance of YOLOv8n on small human detection, where we define
small human to be far-away or occluded persons.
Key Idea: We hypothesize that sharpening specific regions (like facial features) can guide the model in
detecting better. For this, we manually tune the parameters of a simple blob detector to capture facial features,
after which we sharpen these regions and superimpose them onto the original image. This enhanced image is used
as input to the model.
To achieve the best performance, we optimize parameters (freezing backbone and keeping image size as 1280) and finetune
the model, comparing its performance to the original model.



Challenges and Methods
Preprocessing Data: The data had to be preprocessed and converted to YOLO standard format (align to center of bounding box and normalize values) for annotations. New directories had to be created in the standard format for YOLO.
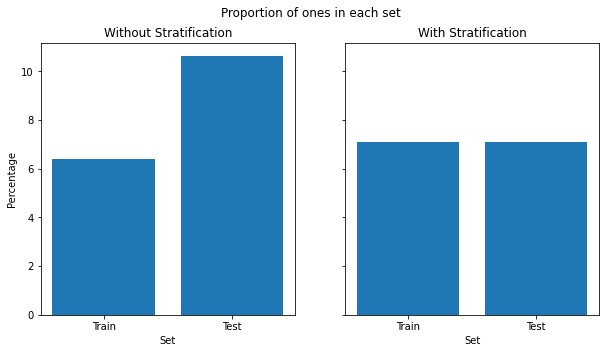
Preparing Small Human Test Annotations: To prepare the dataset for the task, we defined a small human by area and kept only such annotations that passed our area threshold. The large annotations were discarded. We chose the recall metrics to evaluate on this extracted data, as this would give us a good measure of how many small humans have been detected.
- Minimum Area = 200: Sets a lower bound on the pixel area of the bounding box. This restricts blobs from focusing on unnecessary finer details, and instead redirecting it to more general and larger features.
- Minimum Circularity = 0.4: This selects blobs that can range from being circular to rectangular. Since the detector cannot recognize faces as a whole, it might detect parts of the face, which can even be rectangular.
- Minimum Inertia = 0.01: This measures how elongated the blob is. This lower bound filters out identifying lines.

Parameter Optimization
We used the single_clss attribute, which allows the model to train on a single class label. Optimization was conducted on image size and frozen layers, and the optimal values found were 1280 image size and 10 frozen layers (freezing backbone).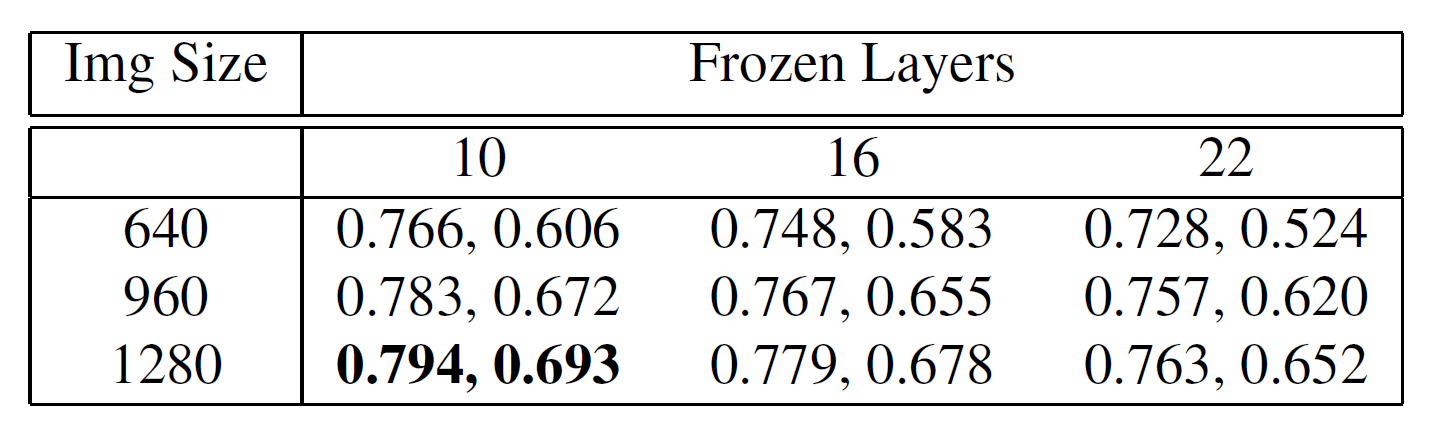
Performance on Small Human Test Dataset
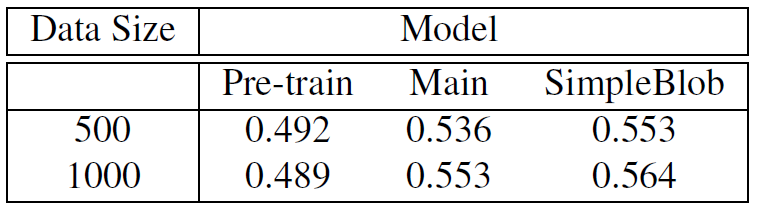
For the task of small human detection, we prioritize recall, as it measures how many small humans are detected. Detecting large humans impacts precision, not recall, making recall the true measure for this task.We validated the model on test datasets of 500 and 1,000 images, comparing the performance of YOLOv8n with three different weights: pretrained, fine-tuned without sharp blobs (Main branch), and fine-tuned with sharp blobs (SimpleBlob branch). As shown in the table below, performance improved across the board, with the model fine-tuned with sharp blobs performing best.
Thus, fine-tuning with blob-enhanced images improves performance by 1.1% in the challenging task of detecting small humans.


I was interested in building a text classifier capable of recognizing fake news in the varying degrees. I dealt with two different datasets, one with six different classes and the other with two classes. Using the R Language, I implemented the Multinomial Naive Bayes Classifier algorithm from scratch (using a few essential libraries) using a SQL-based approach for optimal efficiency. Such an approach proved beneficial as the model was able to train and validate through the second dataset, which had 20800 rows each containing an average of 4544 words, in under 30 seconds. An additional advantage is that such an approach enables easy translatibility into more parallelizable frameworks like SparkR, making it capable of dealing with even larger datasets in lesser time frames.
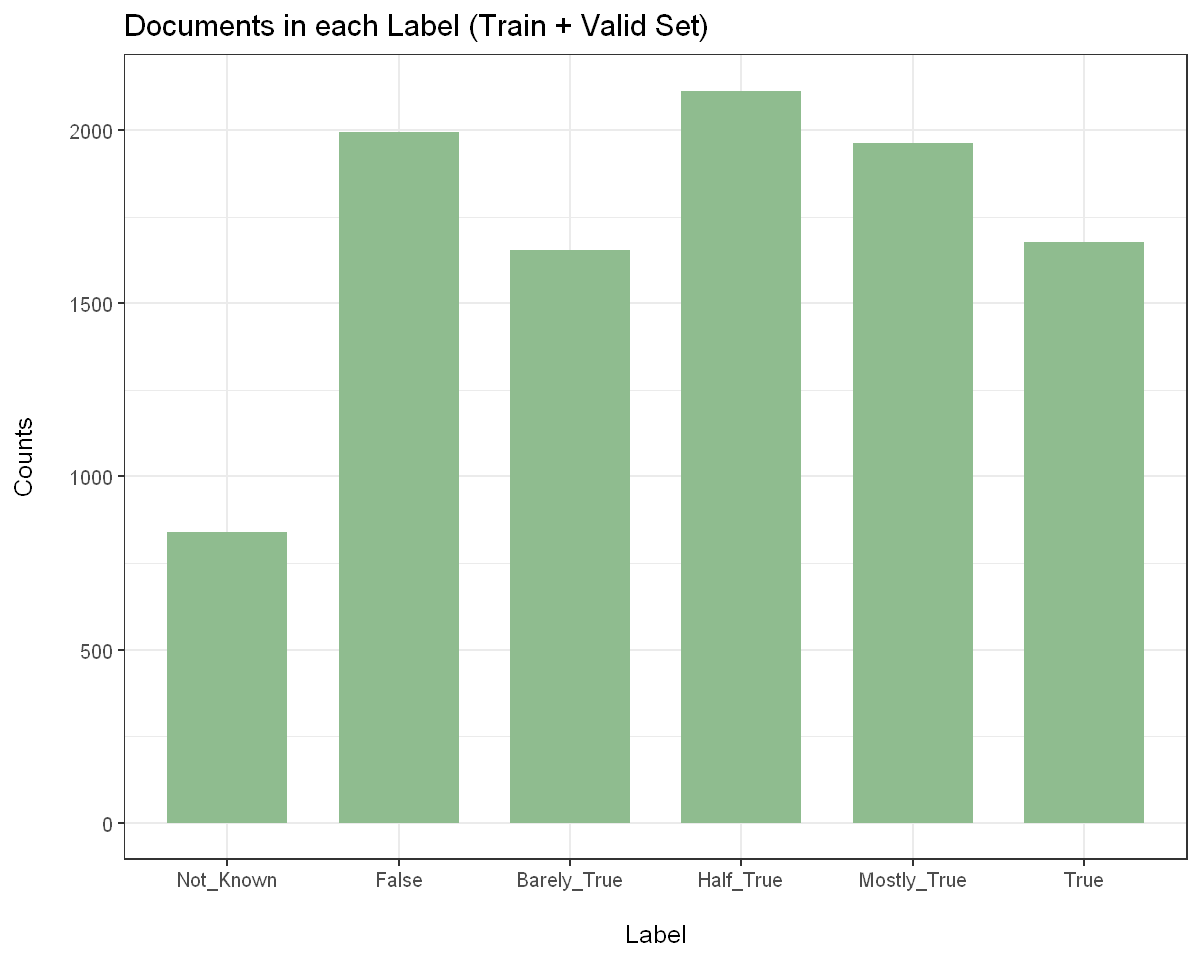
First Dataset : Six Labels
In the first dataset, I manage to use the top 100 words in each label (using 8% of the original vocabulary), and obtain a better performance than when using all the words.Optimal Top-N: 100 (8%), 500 (41%), 750 (60%)
Optimal Top-N: 100 (8%), 500 (41%), 750 (60%)
( Out of 7417 features in vocabulary )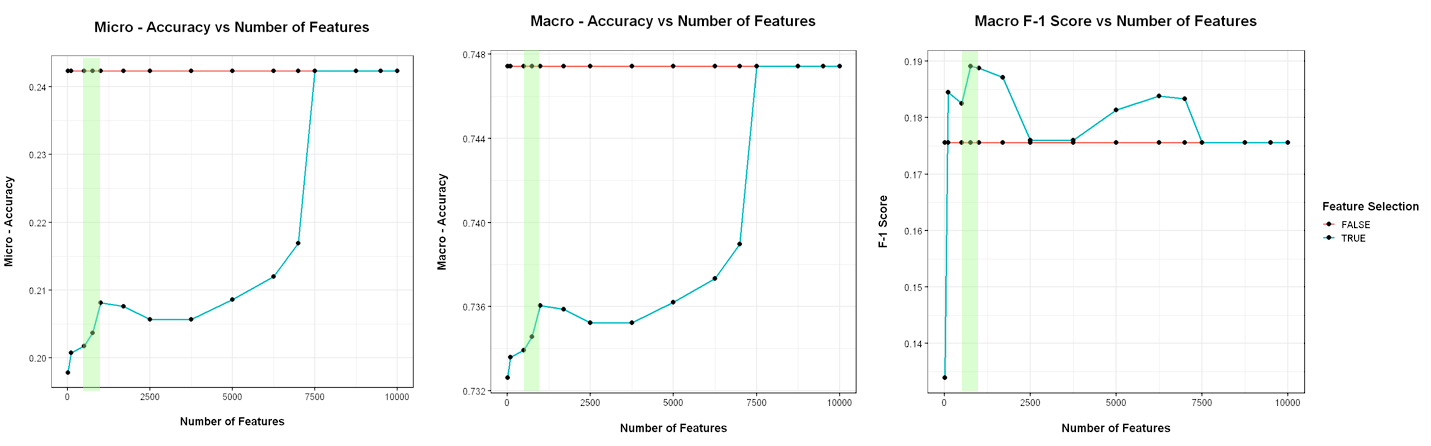
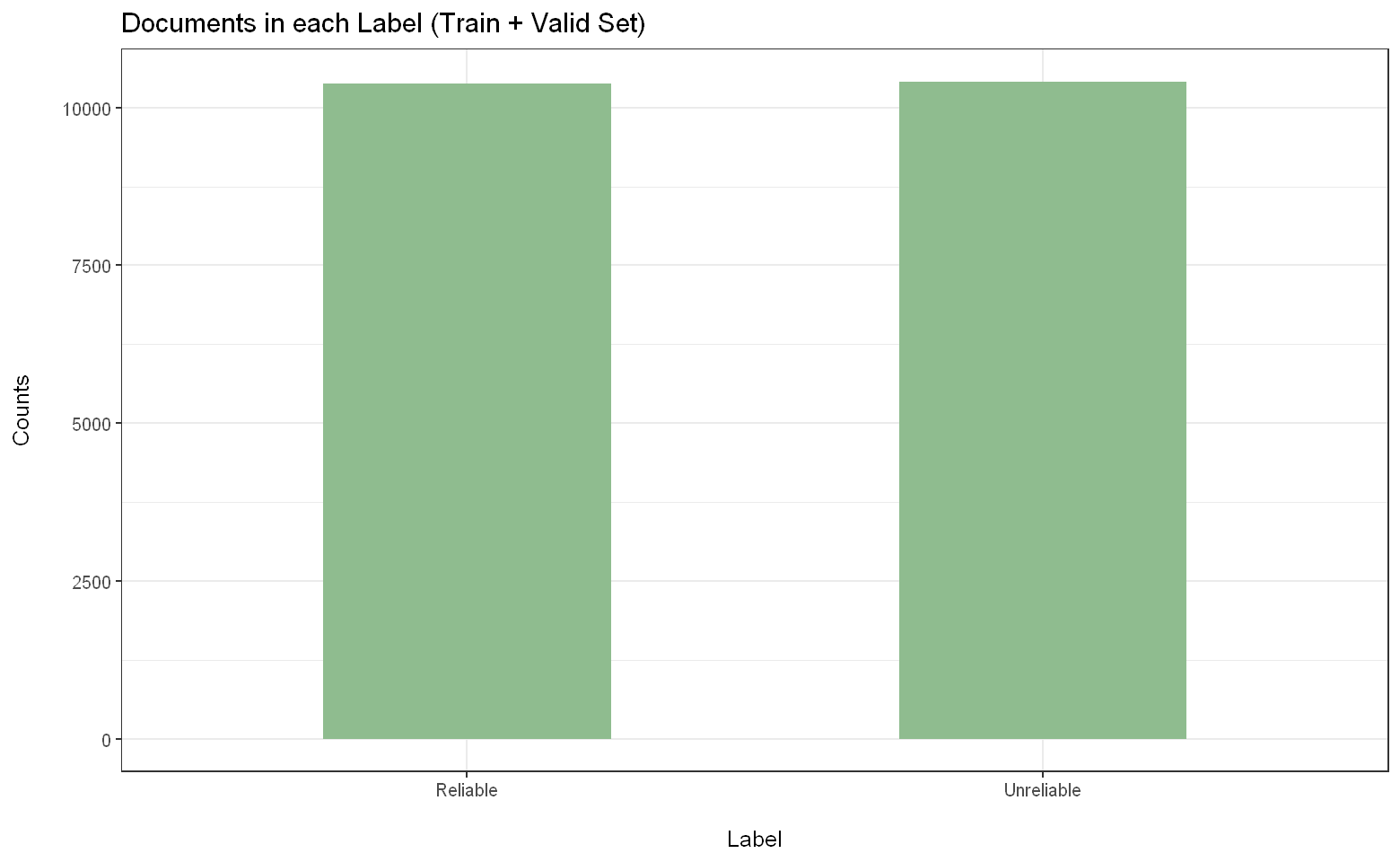
Second Dataset : Two Labels
In the second dataset, using the top 20000 words in each label (28% of the original vocabulary size), I still manage to get a decent performance compared to using all the words.Optimal Top-N: : 20000 (28%), 35000 (49%), 50000 (70%)
Optimal Top-N: : 20000 (28%), 35000 (49%), 50000 (70%)
( Out of 142525 features in vocabulary )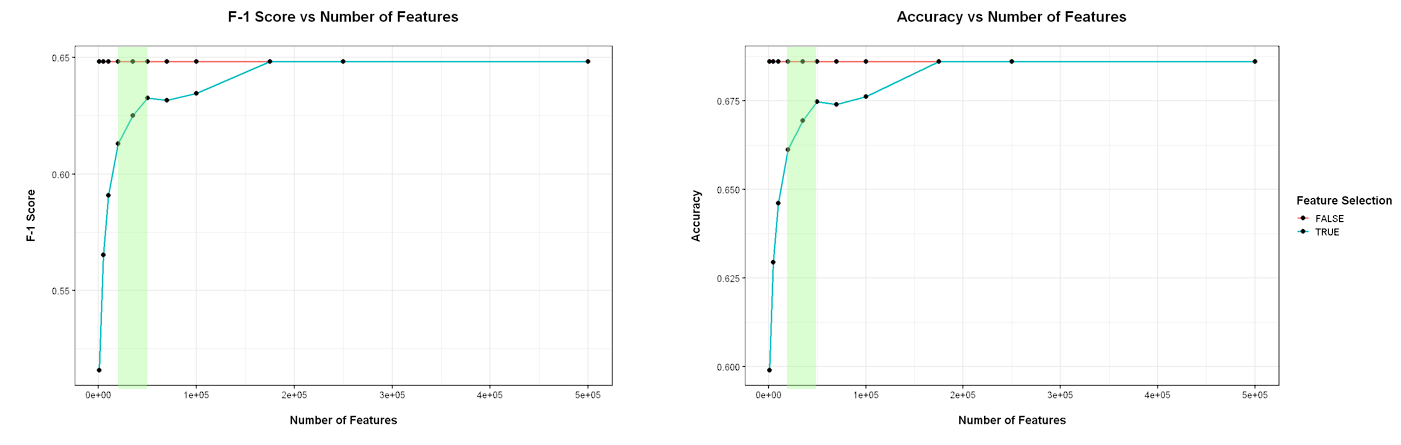
In this project, we were interested in implementing anomaly detection on a large industrial dataset (~5GB). Using the various features of Dask like task graphs and its performance dashboard, we parallelize the tasks and make analyzing big data feasible and efficient. We use an assigned Virtual Cluster consisting of 3 worker nodes for the distributed analyses. With the help of these, we managed to figure out the anomaly events and obtain the variables most correlated to the anomalies.
Challenges and Methods
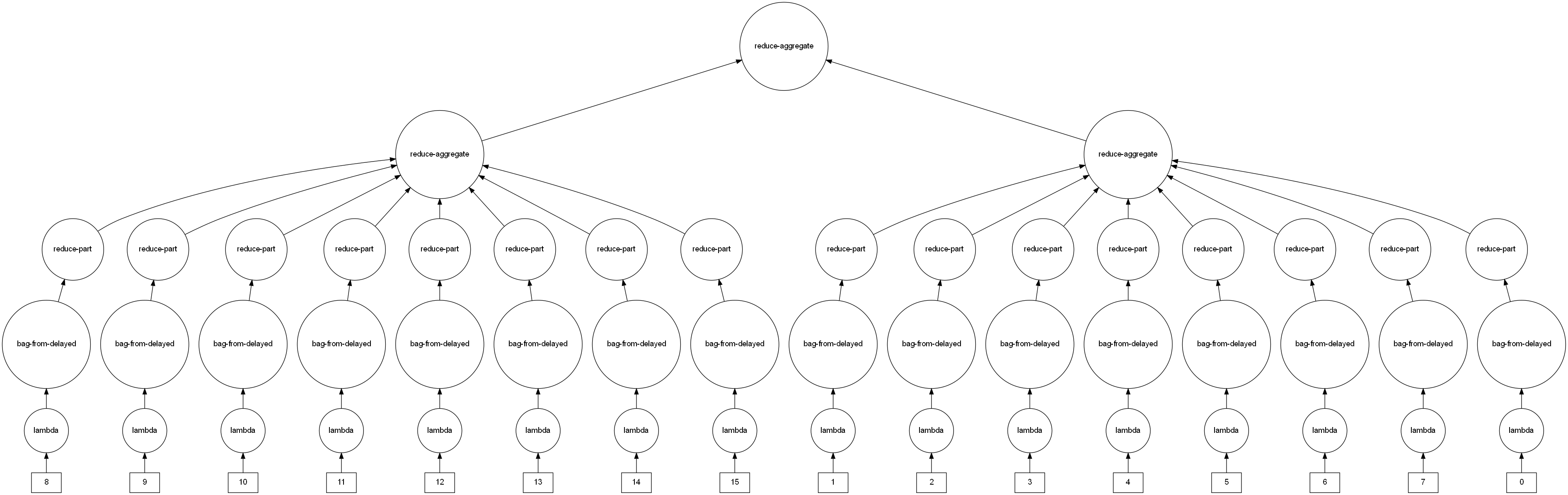
It required wrapping each partitions of the Dask Dataframe into delayed objects, after which they were put in a Dask Bag structure. This enabled us to carry out the reduce phase, and obtain a tree-reduction task graph.
- When normalizing, we had to consider the occurrence of each metric in each time period. We settled on a time period of 200 seconds, where each metric occurs on an average on 97% in a time interval.
- When grouping, we defined a custom aggregation function which aggregates a metric depending on its data type. Integers were max aggregated while float types were mean aggregated.
In order to detect such events, we considered the 4 engines as a single system and defined an integer value to its state in each time interval. The integer value was derived from concatenating the four bit states of the individual engines and obtaining the integer equivalent. Any change in the system's state would correspond to a change in the integer value. In this way, we check for any high frequency changes in the integer values, providing us possible anomaly events.
Anomaly Correlations
We tested the correlations for two cases, one for each device and one considering all devices together. We found that the correlations are drastically low in the latter case, suggesting that the devices act differently possibly due to different environments or configurations. Two of these devices showed high correlations with temperature and pressure parameters, while the other two were not correlated to any of the available parameters.Parallelization
Each task was parallelized utitlizing the task stream and graphs, carrying out distributed analysis to obtain the results.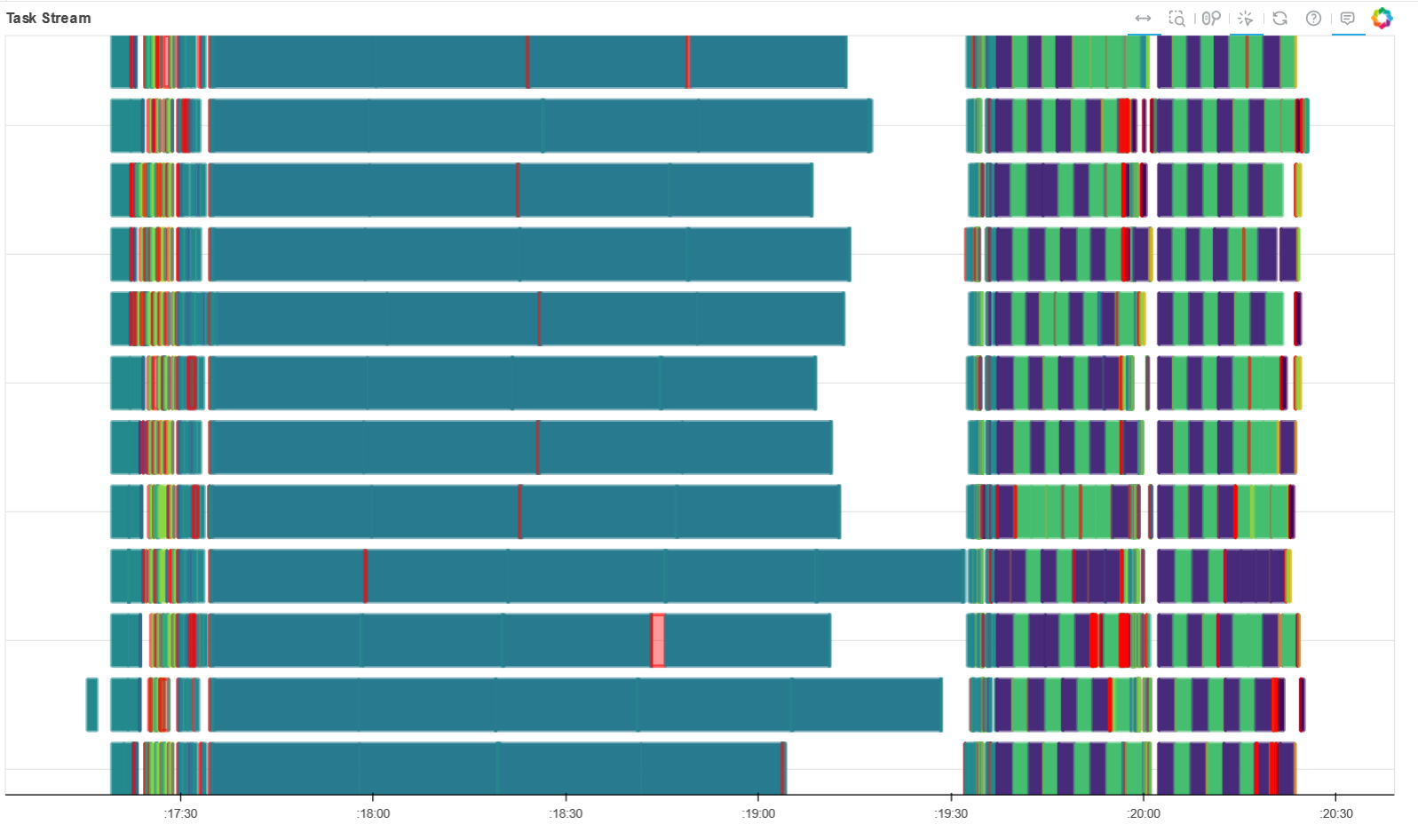
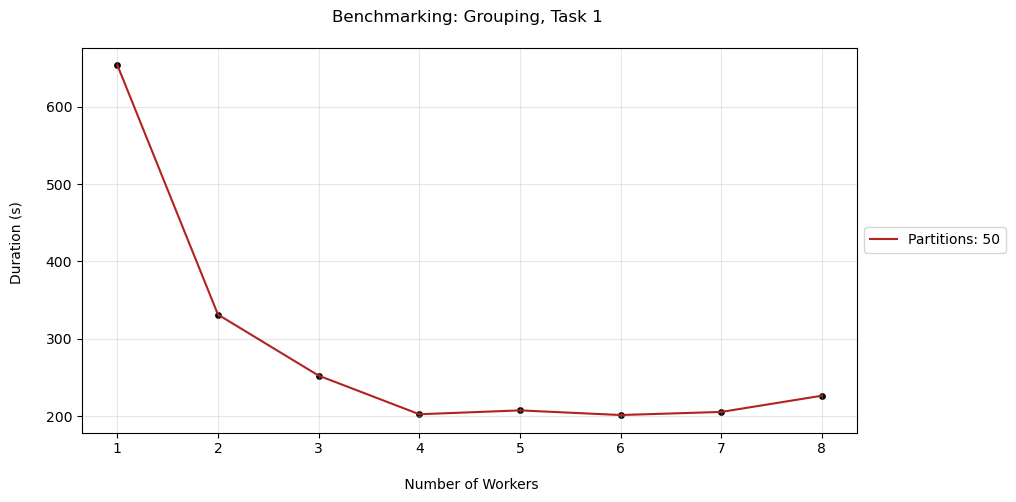
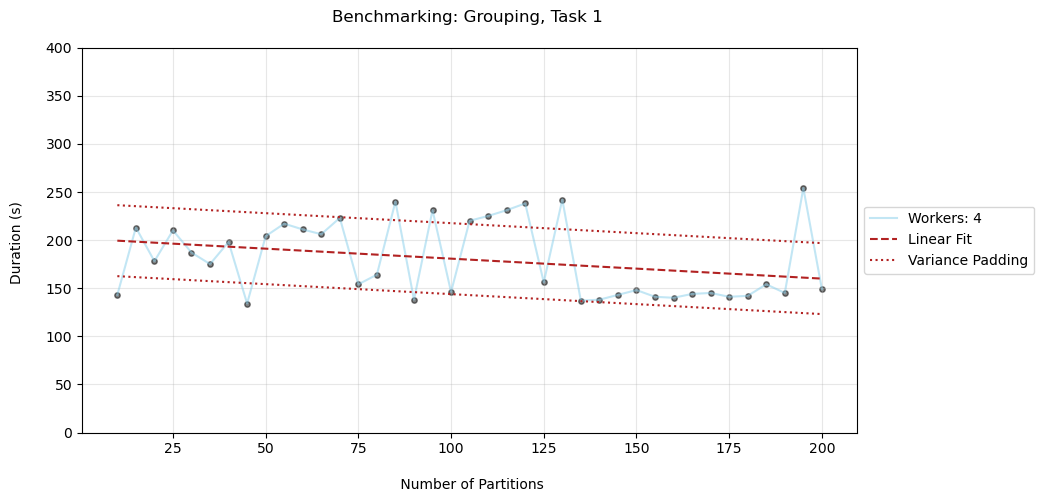
Benchmarking
Comparing the performance variations while varying the number of workers and partitions, we find that the ideal number of workers falls between 4 and 7. In the case of partitions, there isn't a prominent ideal zone, however we see that there is a loose decreasing trend in time as the partitions increase.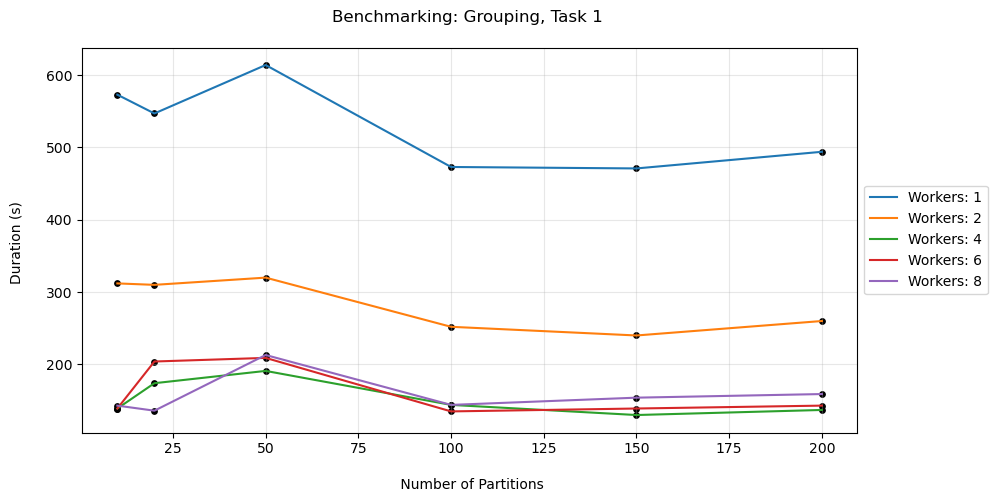
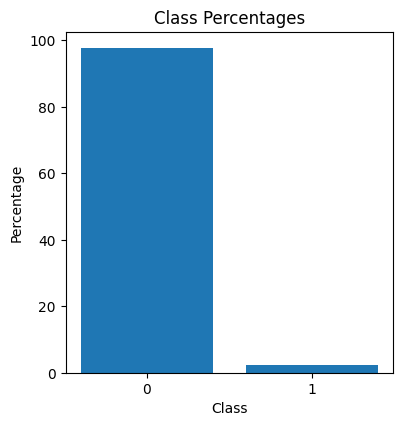
We were interested in detecting crashes (magnetic reconnection) occurring during plasma evolution, based on 65 given parameters. This can be viewed as a binary classification problem for a highly imbalanced time-series dataset. In order to get an idea of how Transformers perform in such tasks against traditional architectures, we conducted a comparative analysis of three models: 1-D Convolutional Neural Network, Deep Neural Network, Transformer. It was found that the Transformer performs the best and provides more reliable predictions in this scenario.
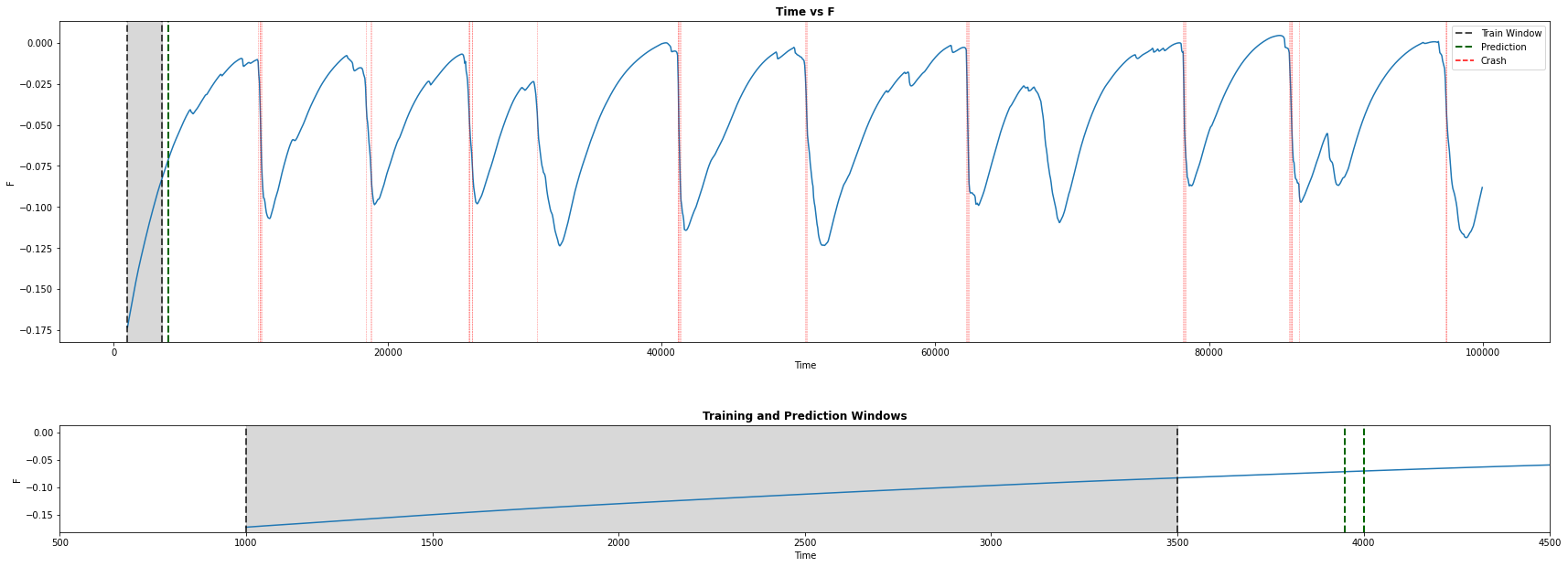
Challenges Faced
This would require more number of datapoints, or utilizing certain methods to overcome this high data imbalance.
Methods Used
Results Obtained
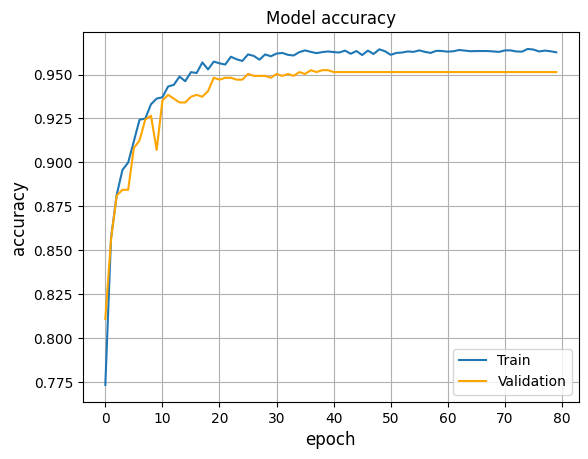
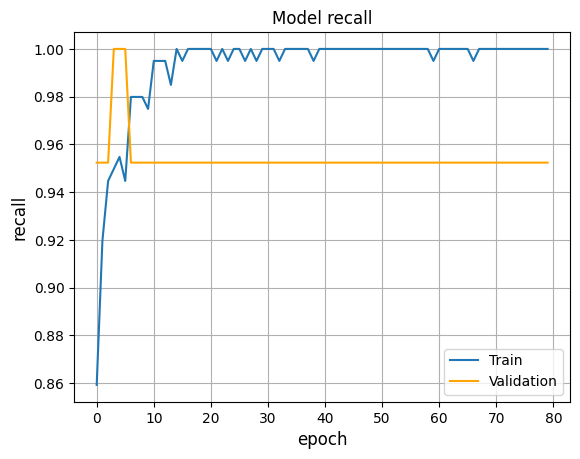
From the metrics used, we focused on both accuracy and recall as they tell if the model is learning and making good predictions. We prioritized recall over precision as the cost of predicting a false negative is greater than that of a false positive, i.e., predicting no crash when there is actually a crash is considered to be highly undesirable. On applying the methods and analyzing the performances with the metrics, we found that the transformer performs the best, providing better and reliable results.
Transformer: Best Model Performance
With two of my peers (Kiamehr Javid, Davide Checchia), we trained a VAE to generate audio samples from a
spatially rich latent space that allowed transition between clusters. The idea behind this project was to
approach audio generation using the tools of Information Theory.
Theory: Supposing the audio is generated from a
lower-dimensional latent space, we try to model this posterior distribution present in this space. Variational
Bayes posits that we use an approximation to the true posterior and try to model the former. It provides a clever
way to approach this using the ELBo, where we try to maximize this term. This, in the end,
provides us with a loss function that constrains the approximate distribution to be around a prior distribution, and
vary according to the likelihood data points. This eventually provides a good approximation for our true posterior distribution.
Dataset: We use the mini-Speech Commands Dataset, a subset of the Google Speech Commands Dataset. This consists of 8 classes (with 1000 samples each)
of short speech keywords. We define a default sample rate of 16k, and filter out any samples not having this rate. For the VAE, we convert these samples to
respective Spectrograms, resulting in a slight information loss (as shown below).
Audio Sample: Stop
Mel Inversed Audio Sample: Stop
The encoder produces two outputs (one for the mean and the other for the standard deviation), which are linked to a stochastic variable for each batch. In a symmetric model, the Decoder is a mirror image of the encoder, while in the asymmetric case, the Decoder contains lesser parameters than the Encoder. This is because the encoder is concerned with the difficult task of mapping the input to the latent space, requiring more parameters.
Complex Symmetric Model
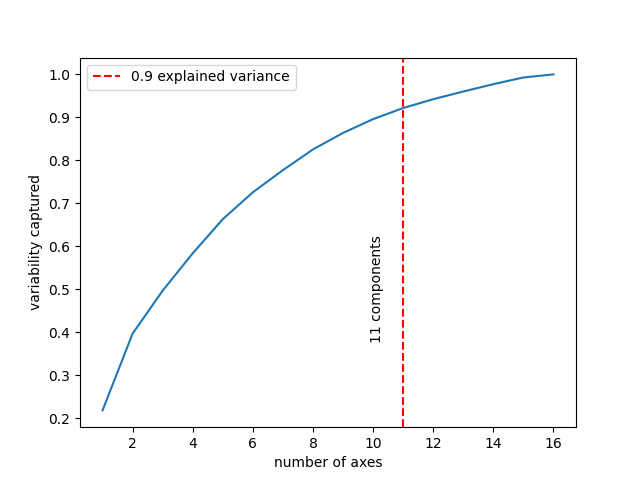
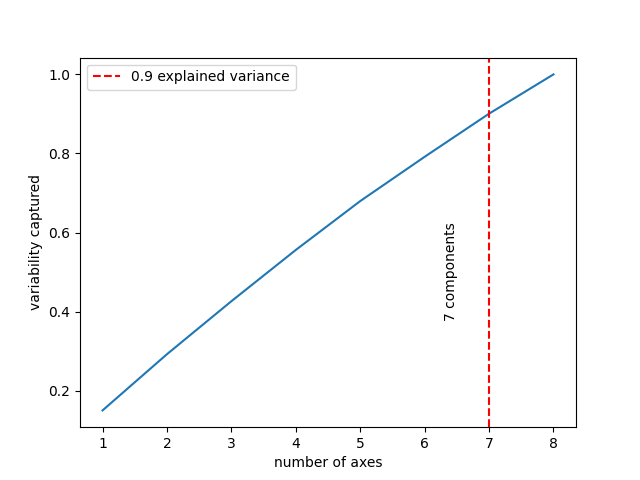
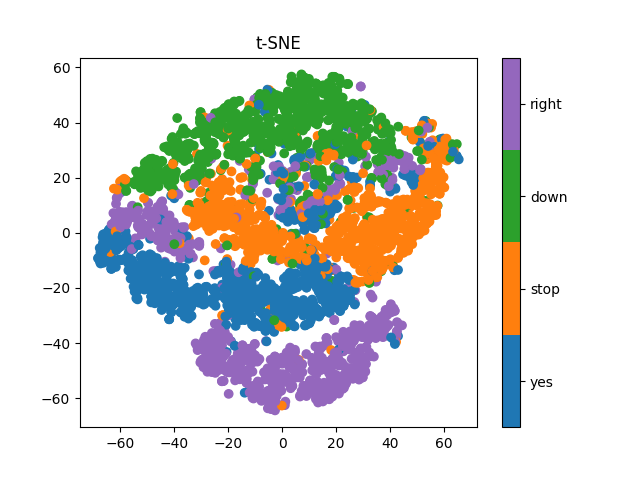
Casting the high-dimensional clusters to two dimensions using t-SNE, we see that there is slight presence of clustering, confirmed by a decent silhoutte score. However, we find that the mean of each cluster (corresponding to each label) does not generate good speech. From the PCA plot, we see that a few latent axes cover most of the variability, which can be interpreted as the existence of redundancy as a lower number of axes manage to cover most of the information. Thus, we can find a lower dimensional space and possibly work with a low complexity model.Original Sample: Right
Regenerated Sample: Right
Cluster Mean: Left

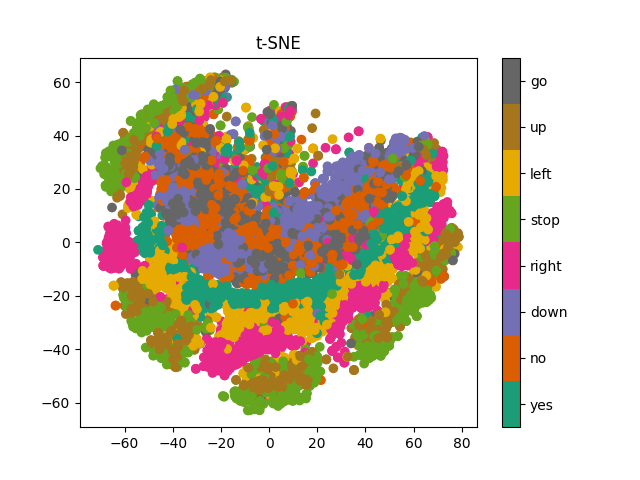
Lightweight Symmetric Model
Using t-SNE, we see that there is better clustering than in the previous model. The PCA plot looks promising, as it points towards redundancy between axes, pushing us to simplify the model even more. From the audio samples, we see that the regenerated sample is perfectly legible, and even the cluster mean turns out to be a good reproduction. We can still try to simplify the model further and see if any improvements can occur.Original Sample: Down
Regenerated Sample: Down
Cluster Mean: Stop
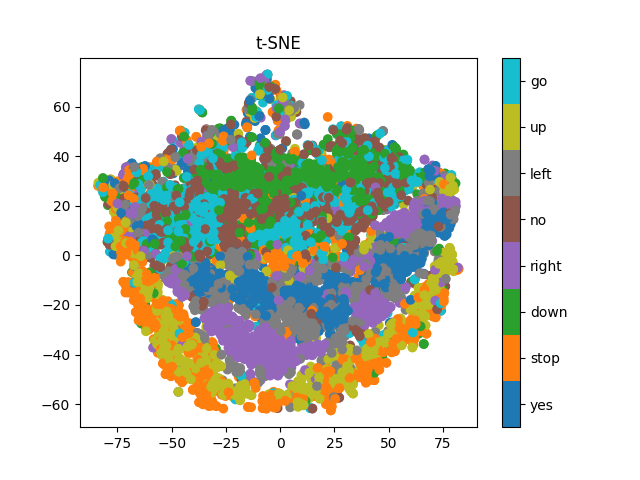
Lightweight Asymmetric Model
Here, the PCA plot tells us that the optimal dimension is higher, as the relation is close to linear, signaling that there is little redundancy, and possibly this dimension is not enough to capture all the complexities of the data. This hints towards choosing a larger latent dimension. Additionally, the regenerated sample, along with the cluster mean sample, is not as good as the lightweight and symmetric model results. We believe the model does not contain the required number of parameters to capture the complexities of the input data. Thus, we conclude that the best model among the three is the lightweight and symmetric model.Original Sample: Yes
Regenerated Sample: Yes
Cluster Mean: Yes
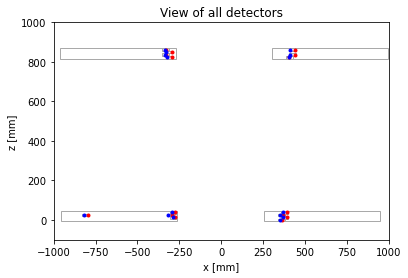
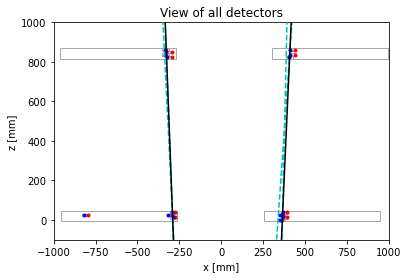
The goal of this project was to identify events with muons passing through the detectors, which is a very rare occurrence. Using a dataset of detections recorded by each detector, we were required to identify muon pair events using a signal selection strategy. As each detector contained four layers of numerous cell-shaped drift tubes, this required geometric analysis to detect pair generation and to separate out the noise events.
Challenges and Methods
However, each detector contains four separate layers of drift tubes. Thus, such linear paths must be established both globally (among detectors) and locally (among layers of drift tubes in each detector).
- In the local case, if there are at least 3 hits in 3 different layers of a detector, that is classified as a possible trajectory.
- In the global case, all four possible linear trajectories are extrapolated and the slopes compared to confirm a muon pair detection.